Software-Defined Assets#
An asset is an object in persistent storage, such as a table, file, or persisted machine learning model. A software-defined asset is a Dagster object that couples an asset to the function and upstream assets that are used to produce its contents.
Software-defined assets enable a declarative approach to data management, in which code is the source of truth on what data assets should exist and how those assets are computed.
A software-defined asset includes the following:
An
AssetKey, which is a handle for referring to the asset.A set of upstream asset keys, which refer to assets that the contents of the software-defined asset are derived from.
An op, which is a function responsible for computing the contents of the asset from its upstream dependencies.
Note: A crucial distinction between software-defined assets and ops is that software-defined assets know about their dependencies, while ops do not. Ops aren't connected to dependencies until they're placed inside a graph.
Materializing an asset is the act of running its op and saving the results to persistent storage. You can initiate materializations from Dagit or by invoking Python APIs. By default, assets are materialized to pickle files on your local filesystem, but materialization behavior is fully customizable using IO managers. It's possible to materialize an asset in multiple storage environments, such as production and staging.
Relevant APIs#
| Name | Description |
|---|---|
@asset | A decorator used to define assets. |
SourceAsset | A class that describes an asset, but doesn't define how to compute it. SourceAssets are used to represent assets that other assets depend on, in settings where they can't be materialized themselves. |
Defining assets#
- Basic software-defined assets
- Assets with dependencies
- Graph-backed assets and multi-assets
- Accessing asset context
- Configuring assets
A basic software-defined asset#
The easiest way to create a software-defined asset is with the @asset decorator.
from dagster import asset @asset def my_asset(): return [1, 2, 3]
By default, the name of the decorated function, my_asset, is used as the asset key. The decorated function forms the asset's op: it's responsible for producing the asset's contents. The asset in this example doesn't depend on any other assets.
Assets with dependencies#
Software-defined assets can depend on other software-defined assets. In this section, we'll show you how to define:
Defining basic dependencies#
The easiest way to define an asset dependency is to include an upstream asset name as an argument to the decorated function.
In the following example, downstream_asset depends on upstream_asset. That means that the contents of upstream_asset are provided to the function that computes the contents of downstream_asset.
@asset def upstream_asset(): return [1, 2, 3] @asset def downstream_asset(upstream_asset): return upstream_asset + [4]
Defining explicit dependencies#
If defining dependencies by matching argument names to upstream asset names feels too magical for your tastes, you can also define dependencies in a more explicit way:
from dagster import AssetIn, asset @asset def upstream_asset(): return [1, 2, 3] @asset(ins={"upstream": AssetIn("upstream_asset")}) def downstream_asset(upstream): return upstream + [4]
In this case, ins={"upstream": AssetIn("upstream_asset")} declares that the contents of the asset with the key upstream_asset will be provided to the function argument named upstream.
Asset keys can also be provided to AssetIn to explicitly identify the asset. For example:
from dagster import AssetIn, asset # If the upstream key has a single segment, you can specify it with a string: @asset(ins={"upstream": AssetIn(key="upstream_asset")}) def downstream_asset(upstream): return upstream + [4] # If it has multiple segments, you can provide a list: @asset(ins={"upstream": AssetIn(key=["some_db_schema", "upstream_asset"])}) def another_downstream_asset(upstream): return upstream + [10]
Defining external asset dependencies#
Software-defined assets frequently depend on assets that are generated elsewhere. Using SourceAsset, you can include these external assets and allow your other assets to depend on them.
For example:
from dagster import AssetKey, SourceAsset, asset my_source_asset = SourceAsset(key=AssetKey("a_source_asset")) @asset def my_derived_asset(a_source_asset): return a_source_asset + [4]
Note: The source asset's asset key must be provided as the argument to downstream assets. In the previous example, the asset key is a_source_asset and not my_source_asset.
You can also re-use assets across repositories by including them as source assets:
from dagster import AssetKey, SourceAsset, asset, repository @asset def repository_a_asset(): return 5 @repository def repository_a(): return [repository_a_asset] repository_a_source_asset = SourceAsset(key=AssetKey("repository_a_asset")) @asset def repository_b_asset(repository_a_asset): return repository_a_asset + 6 @repository def repository_b(): return [repository_b_asset, repository_a_source_asset]
Using source assets has a few advantages over having the code inside of an asset's op load the data:
- Dagit can show asset lineage that includes the source assets. If a different asset definition in a different repository in the same workspace has the same asset key as a
SourceAsset, Dagit can represent the asset lineage across those repositories. - Dagster can use data-loading code factored into an
IOManagerto load the contents of the source asset. - Asset dependencies can be written in a consistent way, independent of whether they're downstream from a source asset or a derived asset. This makes it easy to swap out a source asset for a derived asset and vice versa.
Non-argument dependencies#
Alternatively, you can define dependencies where data from an upstream asset doesn’t need to be loaded by Dagster to compute a downstream asset's output. When used, non_argument_deps defines the dependency between assets but doesn’t pass data through Dagster.
Consider the following example:
upstream_assetcreates a new table (sugary_cereals) by selecting records from thecerealstabledownstream_assetthen creates a new table (shopping_list) by selecting records fromsugary_cereals
from dagster import asset @asset def upstream_asset(): execute_query("CREATE TABLE sugary_cereals AS SELECT * FROM cereals") @asset(non_argument_deps={"upstream_asset"}) def downstream_asset(): execute_query("CREATE TABLE shopping_list AS SELECT * FROM sugary_cereals")
In this example, Dagster doesn’t need to load data from upstream_asset to successfully compute the downstream_asset. While downstream_asset does depend on upstream_asset, the key difference with non_argument_deps is that data isn’t being passed between the functions. Specifically, the data from the sugary_cereals table isn't being passed as an argument to downstream_asset.
Graph-backed assets and multi-assets#
If you'd like to define more complex assets, Dagster offers augmented software-defined asset abstractions:
- Multi-assets: A set of software-defined assets that are all updated by the same op or graph.
- Graph-backed assets: An asset whose computations are separated into multiple ops that are combined to build a graph. If the graph outputs multiple assets, the graph-backed asset is a multi-asset.
Asset context#
Since a software-defined asset contains an op, all the typical functionality of an op - like the use of resources and configuration - is available to an asset. Supplying the context parameter provides access to system information for the op, for example:
@asset(required_resource_keys={"api"}) def my_asset(context): # fetches contents of an asset return context.resources.api.fetch_table("my_asset")
Asset configuration#
Like ops, configuration is also supported for assets. Configuration is accessible through the asset context at runtime and can be used to specify behavior. Note that asset configuration behaves the same as configuration for ops.
For example, the following asset queries an API endpoint defined through configuration:
@asset(config_schema={"api_endpoint": str}) def my_configurable_asset(context): api_endpoint = context.op_config["api_endpoint"] data = requests.get(f"{api_endpoint}/data").json() return data
Refer to the Config schema documentation for more configuration info and examples.
Conditional materialization#
In some cases, an asset may not need to be updated in storage each time the decorated function is executed. In this case you can use the output_required parameter along with yield syntax to invoke this behavior. If the output_required parameter is set to False, you may indicate to the Dagster framework that no data should be persisted to storage by not yielding an output from your computation function. If an output is not emitted during computation, no asset materialization event will be created, the I/O manager will not be invoked, downstream assets will not be materialized, and asset sensors monitoring the asset will not trigger.
@asset(output_required=False) def may_not_materialize(): # to simulate an asset that may not always materialize. random.seed() if random.randint(1, 10) < 5: yield Output([1, 2, 3, 4]) @asset def downstream(may_not_materialize): # will not run when may_not_materialize doesn't materialize the asset return may_not_materialize + [5]
Viewing and materializing assets in Dagit#
Once you've defined a set of assets, you can:
- Load them into Dagit
- View them in Dagit
- Materialize an ad-hoc set of them in Dagit
- Build a job, which materializes a fixed selection of the assets, and can be put on a schedule or sensor
Loading assets into Dagit#
To view and materialize assets in Dagit, you can point it at a module that contains asset definitions or lists of asset definitions as module-level attributes:
dagit -m module_with_assets
If you want Dagit to contain both assets and jobs that target the assets, you can place the assets and jobs together inside a repository.
Viewing assets in Dagit#
All assets#
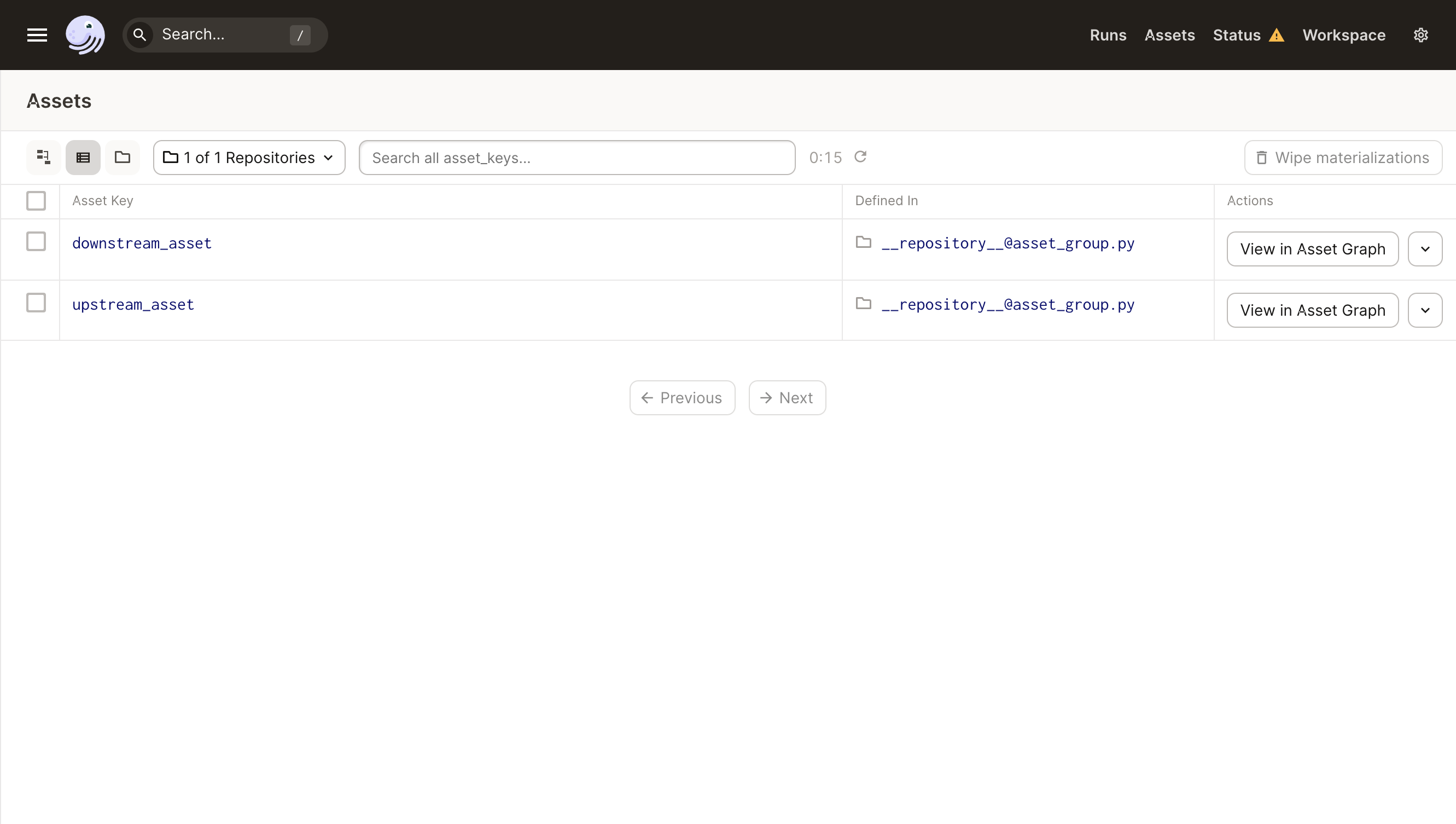
To view a list of all your assets, click Assets in the top-right corner of the page. This opens the Assets page:

Asset Details#
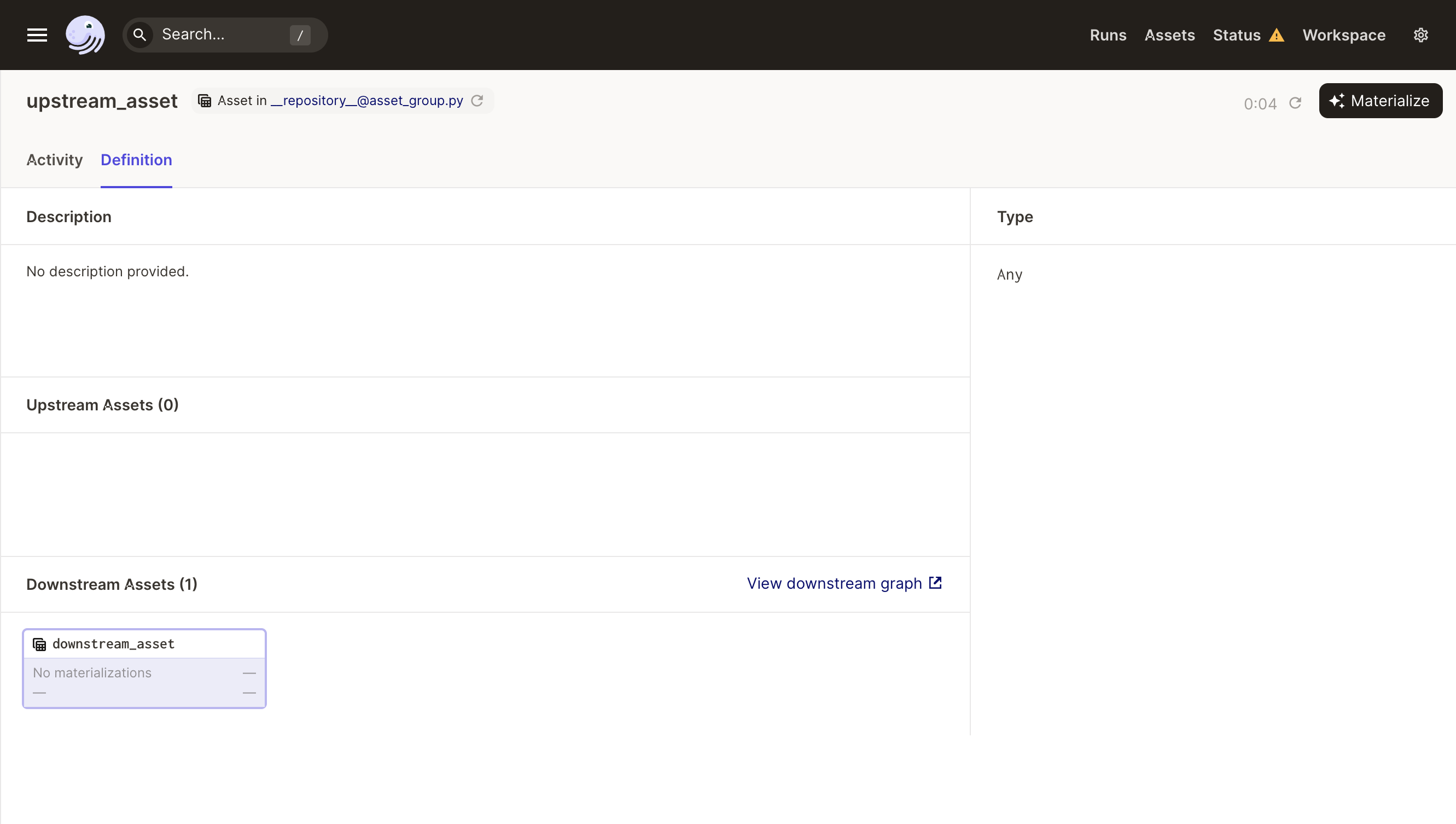
View the Asset Details page for an asset by clicking on its name:
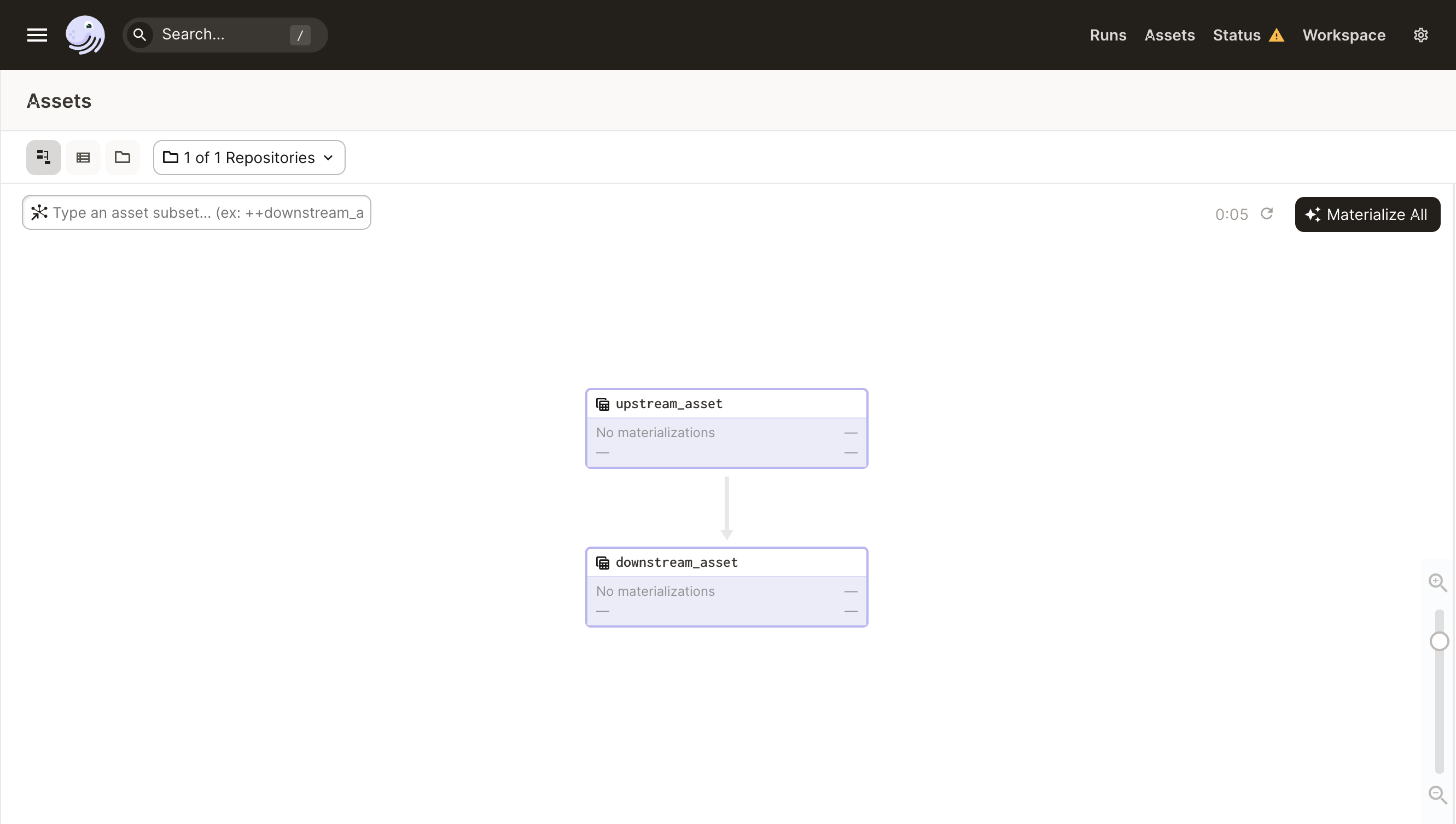
Dependency graph#
To view a graph of all assets and their dependencies, you can:
- Click the graph icon to the upper-left of the Asset Catalog
- Click View in Graph on any asset
Upstream changed indicator#
On occasion, you might see an upstream changed indicator on an asset in the dependency graph or on the Asset Details page:

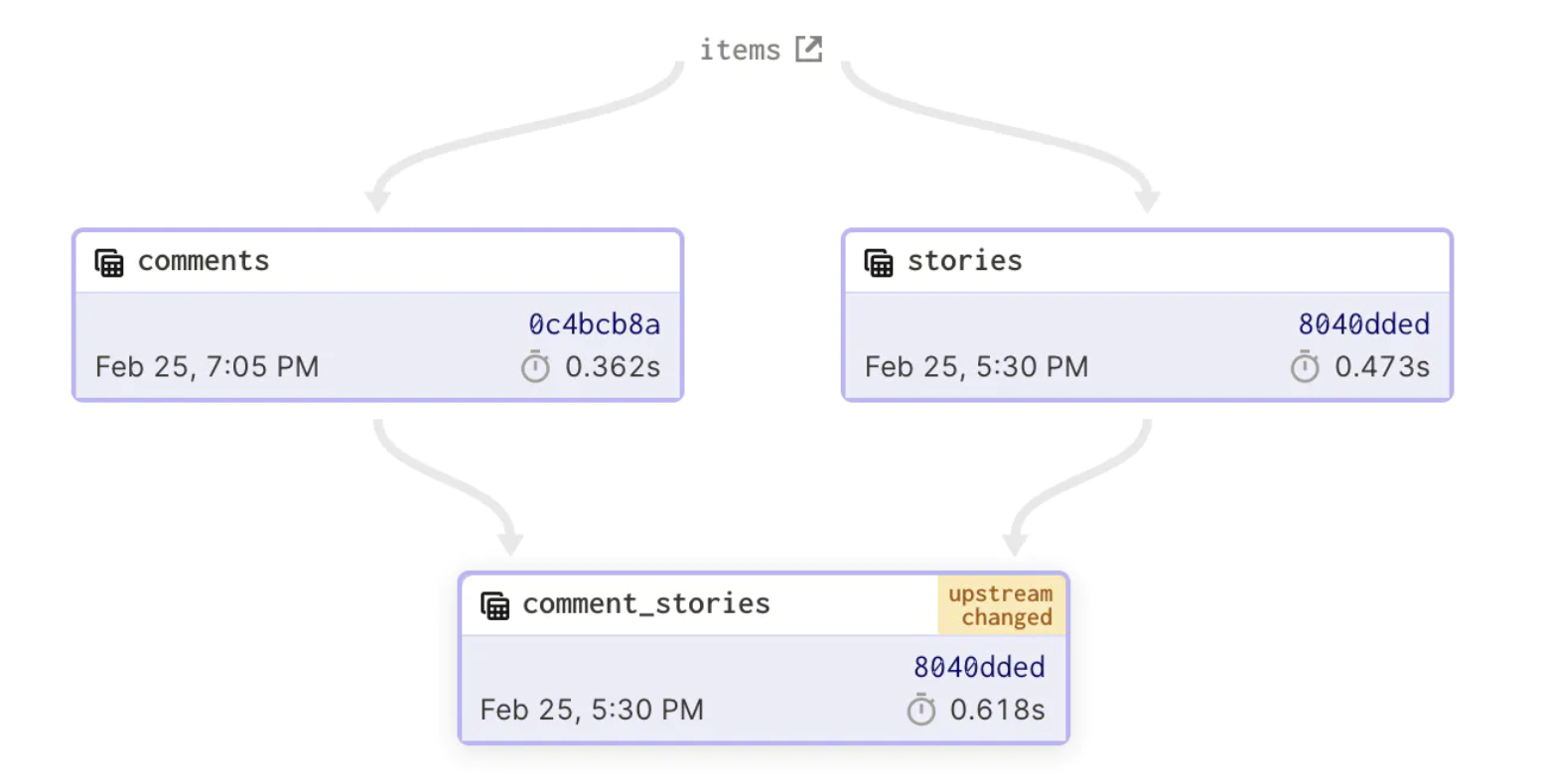
This occurs when a downstream asset's last materialization took place earlier than the asset it depends on. Dagit displays this alert to notify you that the contents of an asset may be stale. For example:
commentsis upstream ofcomment_storiescomment_storiesdepends oncommentscomment_storieswas last materialized on February 25 at 5:30PMcommentswas last materialized on February 25 at 7:05PM
In this case, the contents of comment_stories may be outdated, as the most recent data from comments wasn't used to compute them.
You can resolve this issue by re-materializing the downstream asset. This will re-compute the contents with the most recent data/changes to its upstream dependency.
Currently, the upstream changed indicator won't display in the following scenarios:
- The upstream asset is in another repository or job
- The assets are partitioned
Materializing assets in Dagit#
In Dagit, you can launch runs that materialize assets by:
- Navigating to the Asset Details page for the asset and click the Materialize button in the upper right corner.
- Navigating to the graph view of the Assets page and clicking the Materialize button in the upper right corner. You can also click on assets to collect a subset to materialize.
Building jobs that materialize assets#
Jobs that target assets can materialize a fixed selection of assets each time they run and be placed on schedules and sensors. Refer to the Jobs documentation for more info and examples.
Grouping assets#
To help keep your assets tidy, you can organize them into groups. Grouping assets by project, concept, and so on simplifies keeping track of them in Dagit. Each asset is assigned to a single group, which by default is called "default".
Assigning assets to groups#
In Dagster, there are two ways to assign assets to groups:
- By specifying a group name on an individual asset
- By using the group_name argument when calling
load_assets_from_package_module(recommended)
By default, assets that aren't assigned to a group will be placed in a group named default. Use Dagit to view these assets.
On individual assets#
Assets can also be given groups on an individual basis by specifying an argument when creating the asset:
@asset(group_name="cereal_assets") def nabisco_cereals(): return [1, 2, 3]
From assets in a sub-module#
This recommended approach constructs a group of assets from a specified module in your project. Using the load_assets_from_package_module function, you can import all assets in a module and apply a grouping:
import my_package.cereal as cereal cereal_assets = load_assets_from_package_module( cereal, group_name="cereal_assets", )
If any of the assets in the module already has a group_name explicitly set on it, you'll encounter a Group name already exists on assets error.
Viewing asset groups in Dagit#
To view your asset groups in Dagit, open the left navigation by clicking the menu icon in the top left corner. As asset groups are grouped in repositories, you may need to open a repository to view its asset groups:

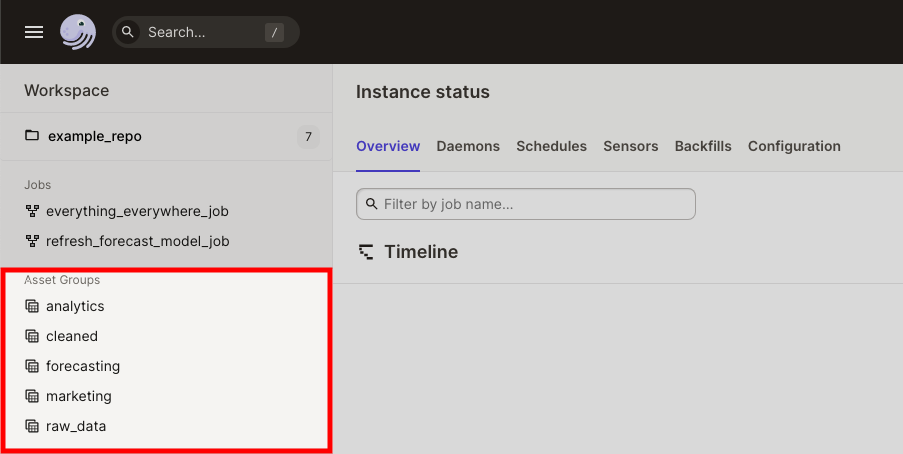
Click the asset group to open a dependency graph for all assets in the group:

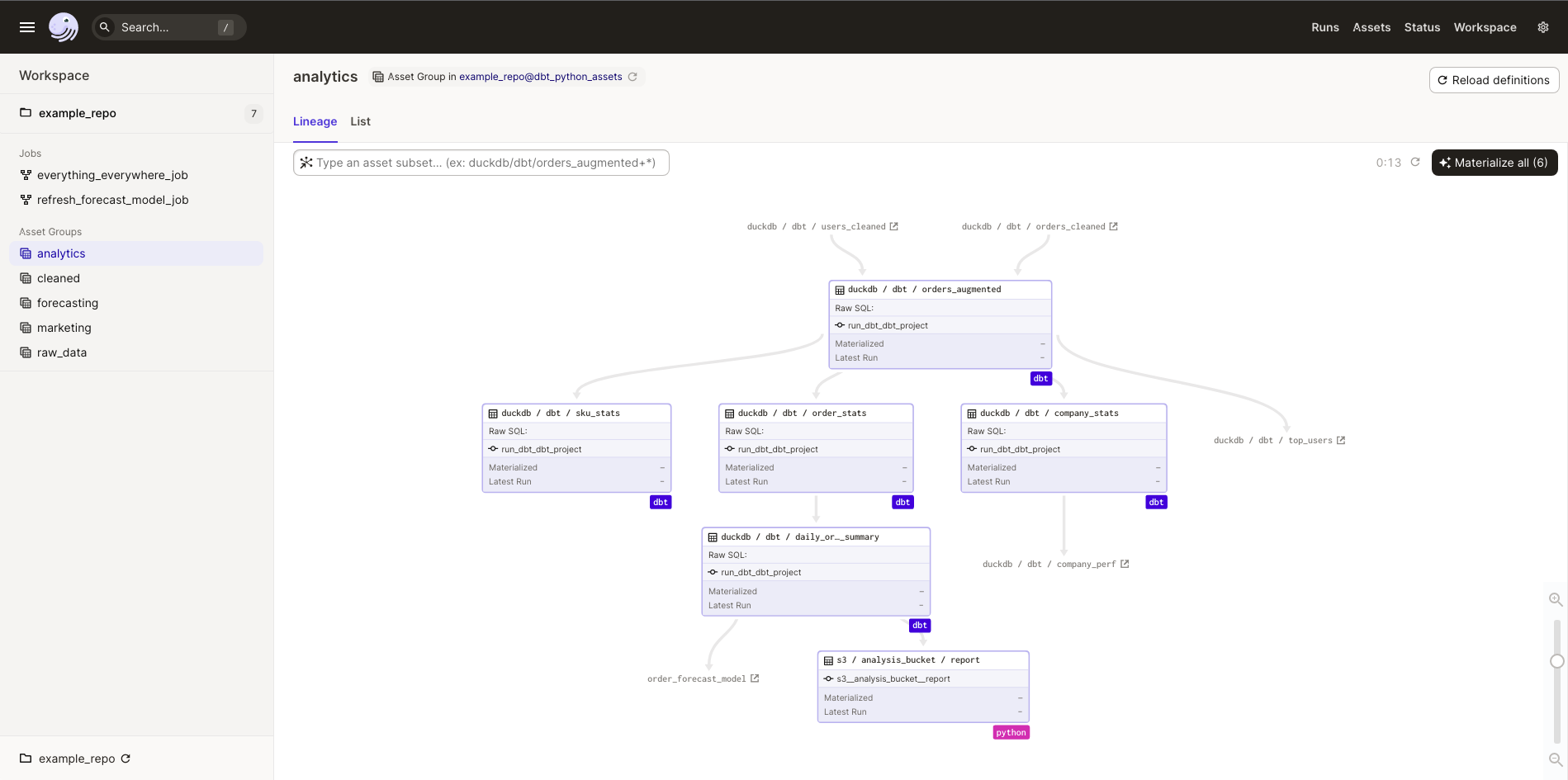
Testing#
When writing unit tests, you can treat the function decorated by @asset as a regular Python function.
Consider a simple asset with no upstream dependencies:
@asset def my_simple_asset(): return [1, 2, 3]
When writing a unit test, you can directly invoke the decorated function:
def test_my_simple_asset(): result = my_simple_asset() assert result == [1, 2, 3]
If you have an asset with upstream dependencies:
@asset def more_complex_asset(my_simple_asset): return my_simple_asset + [4, 5, 6]
You can manually provide values for those dependencies in your unit test. This allows you to test assets in isolation from one another:
def test_more_complex_asset(): result = more_complex_asset([0]) assert result == [0, 4, 5, 6]
If you use a context object in your function, @asset will provide the correct context during execution. When writing a unit test, you can mock it with build_op_context. You can use build_op_context to generate the context object because under the hood the function decorated by @asset is an op.
Consider this asset that uses a resource:
@asset def uses_context(context): return context.resources.foo
When writing a unit test, use build_op_context to mock the context and provide values for testing:
def test_uses_context(): context = build_op_context(resources={"foo": "bar"}) result = uses_context(context) assert result == "bar"
Loading asset values outside of Dagster runs#
It's sometimes useful to load an asset as a Python object outside of a Dagster run, e.g. if you want to do exploratory data analysis on it inside a Jupyter notebook. For this, you can use RepositoryDefinition.load_asset_value:
@repository def repo(): return [load_assets_from_current_module()] asset1_value = repo.load_asset_value(AssetKey("asset1"))
If you want to load the values of multiple assets, it's more efficient to use RepositoryDefinition.get_asset_value_loader, which avoids spinning up resources separately for each asset:
with repo.get_asset_value_loader() as loader: asset1_value = loader.load_asset_value(AssetKey("asset1")) asset2_value = loader.load_asset_value(AssetKey("asset2"))
Examples#
Multi-component asset keys#
Assets are often objects in systems with hierarchical namespaces, like filesystems. Because of this, it often makes sense for an asset key to be a list of strings, instead of just a single string. To define an asset with a multi-part asset key, use the key_prefix argument-- this can be either a list of strings or a single string with segments delimited by "/". The full asset key is formed by prepending the key_prefix to the asset name (which defaults to the name of the decorated function).
from dagster import AssetIn, asset @asset(key_prefix=["one", "two", "three"]) def upstream_asset(): return [1, 2, 3] @asset(ins={"upstream_asset": AssetIn(key_prefix="one/two/three")}) def downstream_asset(upstream_asset): return upstream_asset + [4]
Recording materialization metadata#
Dagster supports attaching arbitrary metadata to asset materializations. This metadata will be displayed on the "Activity" tab of the "Asset Details" page in Dagit. If it's numeric, it will be plotted. To attach metadata, your asset's op can return an Output object that contains the output value and a dictionary of metadata:
from pandas import DataFrame from dagster import Output, asset @asset def table1() -> Output[DataFrame]: df = DataFrame({"col1": [1, 2], "col2": [3, 4]}) return Output(df, metadata={"num_rows": df.shape[0]})
Sometimes it's useful to record the same metadata for all assets that are stored in the same way. E.g. if you have a set of assets that are all stored on a filesystem, you might want to record the number of bytes they occupy on disk every time one is materialized. You can achieve this by recording metadata from an I/O manager that's shared by the assets.
Attaching definition metadata#
Dagster supports attaching arbitrary metadata to asset definitions. This metadata will be displayed on the "Definition" tab of the "Asset Details" page in Dagit. This is useful for metadata that describes how the asset should be handled, rather than metadata describes the contents that were produced by a particular run.
To attach metadata, supply a metadata dictionary to the asset:
@asset(metadata={"owner": "alice@mycompany.com", "priority": "high"}) def my_asset(): return 5
Further reading#
Interested in learning more about software-defined assets and working through a more complex example? Check out our guide on software-defined assets and our example project that integrates software-defined assets with other Modern Data Stack tools.
See it in action#
For more examples of software-defined assets, check out these examples: