Concepts#
This page is a whirlwind tour of Dagster's core concepts and how to use them to build and operate your data pipelines.
Software-defined assets#
The most common way to build a data pipeline in Dagster is with software-defined assets. With software-defined assets, you define your data pipeline in terms of the data assets that it produces and the data dependencies between those assets. A data asset is an object in persistent storage, such as a table, file, or persisted machine learning model.
You create a software-defined asset by writing Python code. That code specifies:
- The upstream assets that the asset depends on
- The function (op) that's used to derive the asset from its upstream assets
You can also load asset definitions in bulk from systems like dbt.
Here's an example of some code that defines a set of software-defined assets, and the visualization of those assets in Dagster's web UI:
from dagster import asset from pandas import DataFrame, read_html, get_dummies from sklearn.linear_model import LinearRegression as Regression @asset def country_stats() -> DataFrame: df = read_html("https://tinyurl.com/mry64ebh")[0] df.columns = ["country", "continent", "pop_change"] df["pop_change"] = df["pop_change"].str.rstrip("%").astype("float") return df @asset def change_model(country_stats: DataFrame) -> Regression: data = country_stats.dropna(subset=["pop_change"]) dummies = get_dummies(data[["continent"]]) return Regression().fit(dummies, data["pop_change"]) @asset def continent_stats(country_stats: DataFrame, change_model: Regression) -> DataFrame: result = country_stats.groupby("continent").sum() result["pop_change_factor"] = change_model.coef_ return result
Once you have a graph of assets, you can launch runs that materialize individual assets or sets of assets. Materializing an asset means computing its contents and writing them to persistent storage.
How software-defined assets relate to other Dagster concepts:
- Schedules and sensors materialize assets automatically, at fixed intervals or according to user-provided criteria.
- A partitioned asset is an asset that's composed of a set of partitions, which can be materialized and tracked independently.
- I/O managers allow defining assets as "pure" functions, like in the example above. The I/O manager handles loading the input values and storing the return values, usually in a data lake or data warehouse. Not all assets need to be pure functions or use I/O managers.
- You can write jobs that point to a fixed selections of assets and run them as a single unit.
- Under the covers, assets use ops or graphs to represent the computations that produce them.
Ops and graphs#
In some situations, it's doesn't make sense to define your pipelines purely in terms of software-defined assets, and you want a lower-level API that gives you more control. For example:
- If the goal of your pipeline isn't to produce data assets
- If the assets produced by your pipeline aren't known before it runs
In those cases, you can define ops and connect those ops together in op graphs. Ops are basically functions on steroids. Op graphs hook up the outputs of ops to the inputs of other ops.
Here's an example of some code that defines a graph of ops, and the visualization of that graph in Dagster's web UI:
from dagster import graph, op from dagster_snowflake import snowflake_resource from dagster_slack import slack_resource from .config import SLACK_CONFIG, SNOWFLAKE_CONFIG @op(required_resource_keys={"snowflake"}) def find_stale_tables(context) -> list[str]: return [ record[0] for record in context.resources.snowflake.execute_query( """select table_schema || '.' || table_name from information_schema.tables where last_altered > dateadd(day, -30, current_timestamp)""", fetch_results=True, ) ] @op(required_resource_keys={"slack"}) def post_stale_tables(context, tables: list[str]) -> None: context.resources.slack.chat_postMessage( channel="#stale-tables", text="Stale tables:\\n" + "\\n- ".join(tables) ) @graph def report_stale_tables(): post_stale_tables(find_stale_tables())
If you're using software-defined assets, you're also using ops, just usually not directly. Each software-defined asset has an op or graph that's responsible for computing its contents.
How ops and graphs relate to other Dagster concepts:
- You can write a job that contains a graph of ops. This allows running that graph from the command line, from Dagster's web UI, or from a schedule or sensor.
- Under the covers, assets use ops or graphs to represent the computations that produce them.
Jobs#
Jobs are units of bulk execution and monitoring.
If you’re building pipelines with software defined assets, you can write jobs that each point to a selection of assets. Launching a job will materialize all the assets it points to.
from dagster import AssetSelection, define_asset_job my_job = define_asset_job("my_job", selection=AssetSelection.assets(asset1, asset2))
If you're using op graphs, you can write a job that contains a graph of ops. Launching the job will execute all the ops. Think of ops and graphs like functions and jobs like scripts: to run an op or graph, you have to invoke it inside a Python process.
You can run jobs from the command line, from Dagster's web UI, or automatically with schedules or sensors.
In Dagster's web UI you can see the history of all the runs for each job:

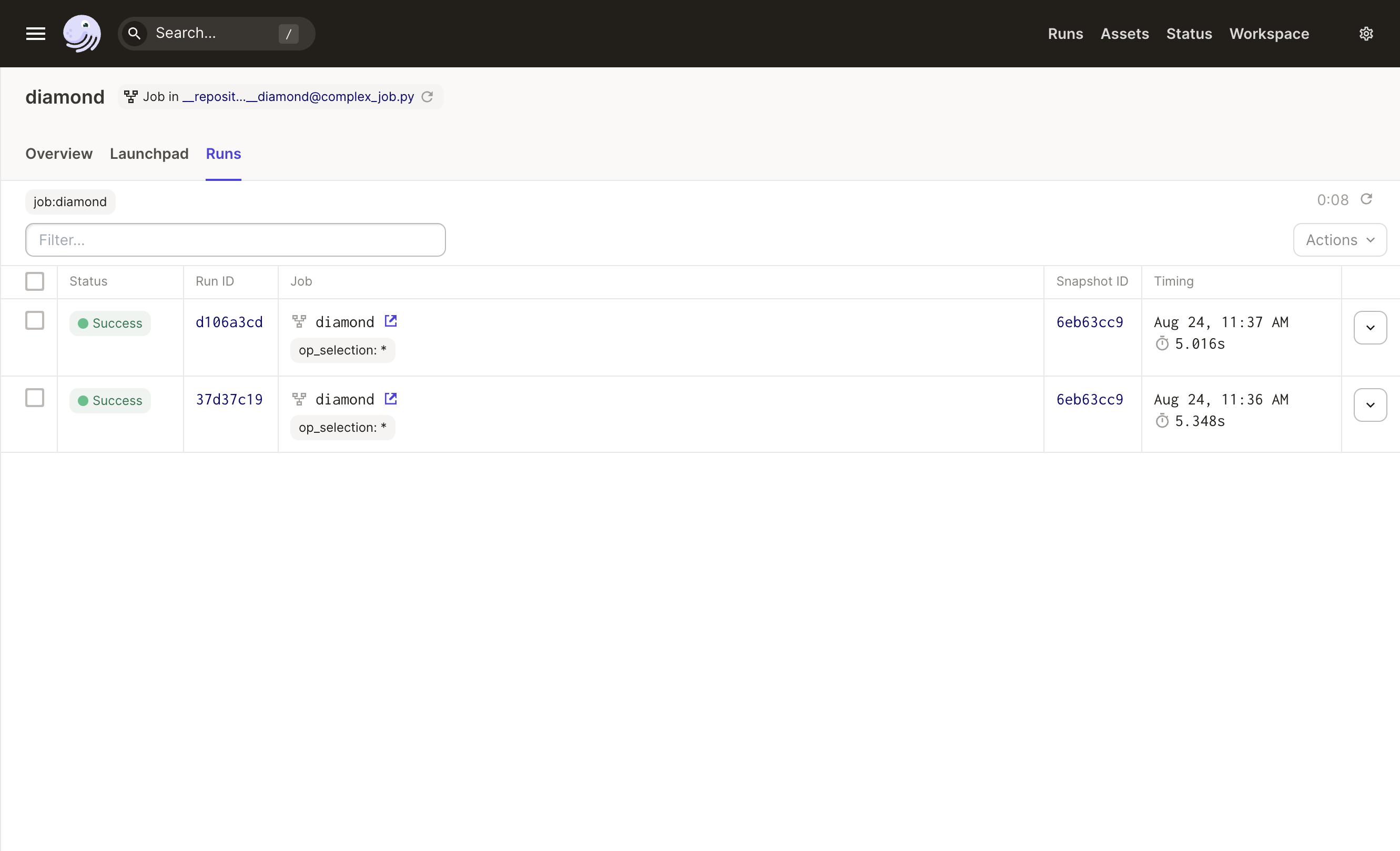
How jobs relate to other Dagster concepts:
- You can write a job that points to a fixed selection of assets and runs them as a single unit.
- You can write a job that contains a graph of ops.
- Schedules and sensors enable running jobs automaticaly and repeatedly.
Partitions#
A partitioned asset is an asset that's composed of a set of partitions, which can be materialized and tracked independently. For example, the asset might refer to a directory in S3 where each file inside it corresponds to a date. You can launch runs that materialize individual partitions, which would mean creating or overwriting one of those date files.
You can launch backfills over partitioned assets: a backfill is a collection of runs that each target one partition.
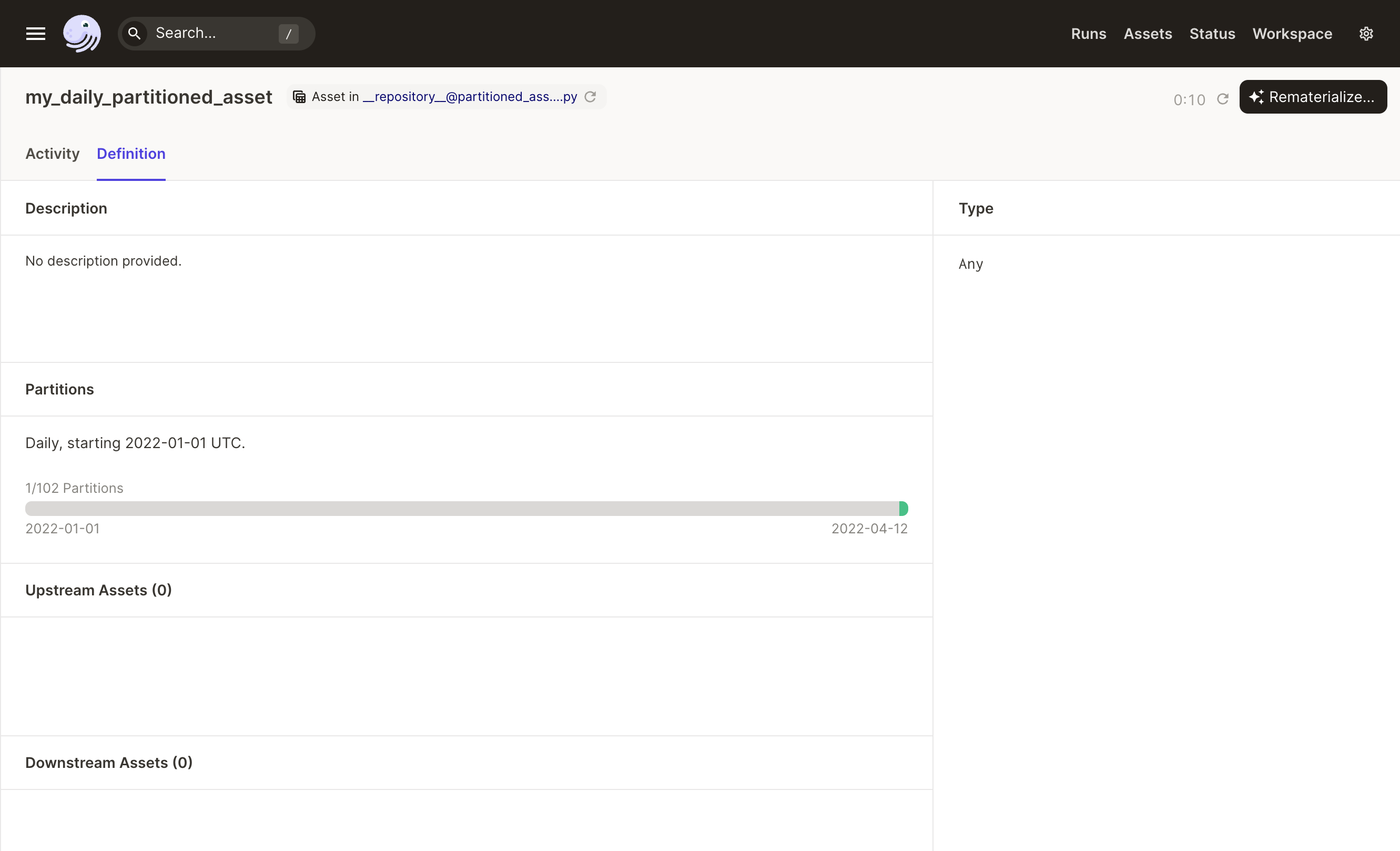
Here's an example of a partitioned asset:
import pandas as pd from dagster import DailyPartitionsDefinition, asset @asset(partitions_def=DailyPartitionsDefinition(start_date="2022-01-01")) def my_daily_partitioned_asset(context) -> pd.DataFrame: partition_date_str = context.asset_partition_key_for_output() return pd.read_csv(f"coolweatherwebsite.com/weather_obs&date={partition_date_str}")
and a representation in Dagit of which partitions have been materialized:
Schedules and sensors#
Schedules and sensors let you launch runs automatically and repeatedly. Schedules launch runs on fixed intervals. Sensors let you write code that determines whether runs should be launched - usually in response to observing that new data has arrived or something about the world outside Dagster has changed.
Here's an example of how you'd schedule a set of assets to be materialized every day:
from dagster import AssetSelection, ScheduleDefinition, define_asset_job my_schedule = ScheduleDefinition( job=define_asset_job("orders_job", selection=AssetSelection.assets(raw_orders, orders)) )
Here's an example of how you'd materialize a set when new upstream data arrives:
from dagster import AssetSelection, RunRequest, define_asset_job, sensor @sensor(job=define_asset_job("orders_job", selection=AssetSelection.assets(raw_orders, orders))) def my_sensor(): if new_data_has_arrived(): return RunRequest()
How schedulers and sensors relate to other Dagster concepts:
- Schedules and sensors target jobs.
- Schedules are often used with partitions: for example, it's common to write a schedule that runs at the end of every day and materializes the partition for that day.
I/O managers#
To reduce boilerplate and make pipelines more testable, Dagster encourages separating business logic from I/O.
You can define your assets and ops as "pure" functions that accept data and return data, then separately define I/O managers that know how to write and read that data to and from storage systems like filesystems or data warehouses. The same I/O manager can be shared across many different assets or ops.
Here's an example of using an I/O manager to assign a pair of assets to be stored in a particular directory on the local filesystem:
from dagster import asset, repository, with_resources from pandas import DataFrame snowflake_io_manager = ... s3_io_manager = ... @asset(io_manager_key="warehouse") def events() -> DataFrame: ... @asset(io_manager_key="warehouse") def logins(events) -> DataFrame: ... @asset(io_manager_key="object_store") def login_bot_classifier(logins) -> DataFrame: ... @repository def my_repo(): return with_resources( [events, logins, login_bot_classifier], {"warehouse": snowflake_io_manager, "object_store": s3_io_manager}, )

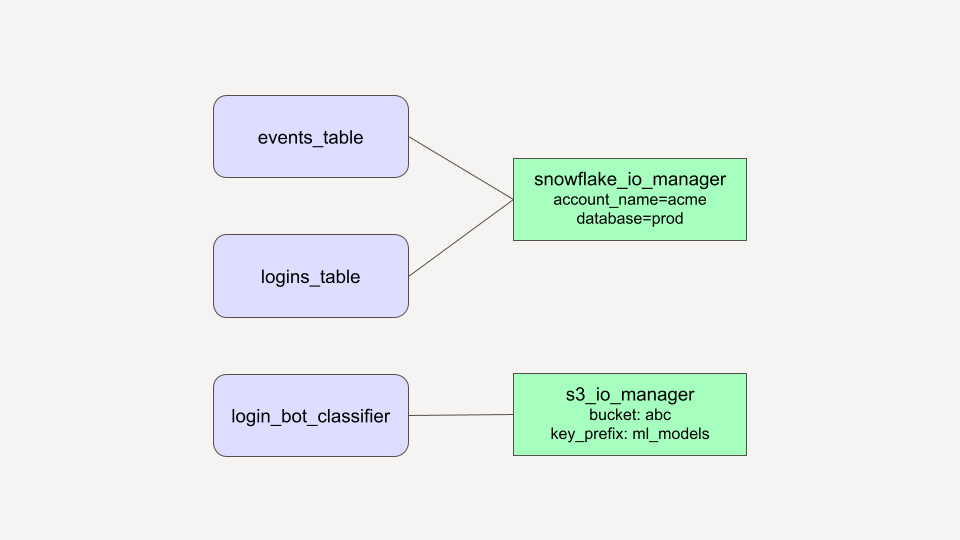
Dagster doesn't require that you use IO managers: you can also write assets and ops as "impure" functions that have side effects and don't accept or return any values.
How I/O managers relate to other Dagster concepts:
- I/O managers are a kind of resource.
- All software-defined assets that are defined as pure functions have an I/O manager.
- All outputs of ops that are defined as pure functions have an I/O manager.
Resources#
Resources help you model external systems that your ops or software-defined assets interact with. For example, a resource might be a connection to a data warehouse like Snowflake or a service like Slack.
Resources enable a simple form of dependency injection: you can define software-defined assets and ops without specifying the implementations of the resources that they interact with. It then becomes easy to vary the resources in different environments. For example, in your production environment, you could connect to your production Slack instance, in your staging environment, you could connect to a staging Slack instance, and in unit tests, you could use a mock Slack instance.
How resources relate to other Dagster concepts:
- I/O managers are a kind of resource.
- Software-defined assets can use resources.
- Ops can use resources.
Repositories and workspaces#
Dagster repositories (not to be confused with git repositories) and workspaces are how you tell Dagster how to execute your code.
To do its job, Dagster needs to execute the Python code you write. It does this in two settings:
- When you run a Dagster job or materialize a software-defined asset – whether from the web UI, the command line, or a schedule or sensor – Dagster executes your code to carry out that run.
- Even before you launch any runs, Dagster's web UI and scheduler need to know about what assets and jobs to display and what schedules and sensors to evaluate. To load these definitions, Dagster needs to execute your code.
In Dagster, a repository is a Python object, defined at module scope, that holds a set of asset, job, schedule, and sensor definitions. When you launch Dagster's web UI or scheduler daemon, you tell it the Python module and attribute name within that module of every Dagster repository that you want it to know about.
Different Dagster repositories typically correspond to different Docker containers. This allows you to avoid having all your pipelines rely on the same set of Python dependencies.
Here's an example of defining a Dagster repository with a set of assets, jobs, and schedules:
from dagster import load_all_assets_from_current_module, repository @repository def repo(): return [load_all_assets_from_current_module(), job1, job2, schedule1, sensor1]
A workspace is a collection of all the repositories that are loaded within a single Dagster deployment.